Azure Search indexer with JSON array
azure search knowledge-mining
This article describes how to work with more complex JSON documents within Azure Search indexer.
September 17, 2019
Azure Search is powerful service for knowledge extraction. One of the nice things it can do is ingest and parse various types of files from Azure Storage and make them searchable. This article describes how to work with more complex JSON documents.
While it's possible to use the Azure Portal for index definition, recommended ways for iterative development are either REST or SDK. I used the C# SDK, because that's closer to me.
tl;dr
Key elements of building an index for JSON documents with multiple documents inside one file:
- use
jsonArrayparsing mode when creating the indexer:
Parameters = new IndexingParameters()
{
Configuration = new Dictionary<string, object>()
{
{ "dataToExtract", "contentAndMetadata" },
{ "parsingMode", "jsonArray" }
}
}
- use
AzureSearch_DocumentKeymapping to get unique ID per JSON object - arrays can be accessed in indexers using the
/NBest/0/Displaysyntax (1st element of array)
Indexing complex JSON from Storage
Indexers are great for pumping data into search index from various sources. They can be executed once or repeatedly, per defined schedule, and they can map source data to custom search fields. One of the great things they can do is parsing JSON files into search documents. There are three modes available:
json- Each blob/file is single document.jsonArray- Each blob contains multiple documents (objects) in the form of JSON array.jsonLines- Each blob contains multiple JSON objects, separated by new lines.
By default indexer parses blobs as simple text, without any object representation.
I used jsonArray mode because my typical JSON file had structure similar to this one:
[
{
"OffsetInSeconds": 0.98,
"DurationInSeconds": 15,98,
"SpeakerId": null,
"NBest": [
{
"Confidence": 0.901238,
"Sentiment": null,
"Prop1": "somestring",
"Prop2": "somestring",
"Display": "Somestring."
}
]
},
{
"OffsetInSeconds": 28.08,
..... the same structure as previous....
}
]
That is - text file with JSON array containing objects with properties and nested arrays.
NuGet & SearchServiceClient
The C# SDK path begins by installing the appropriate NuGet package:
Install-Package Microsoft.Azure.Search
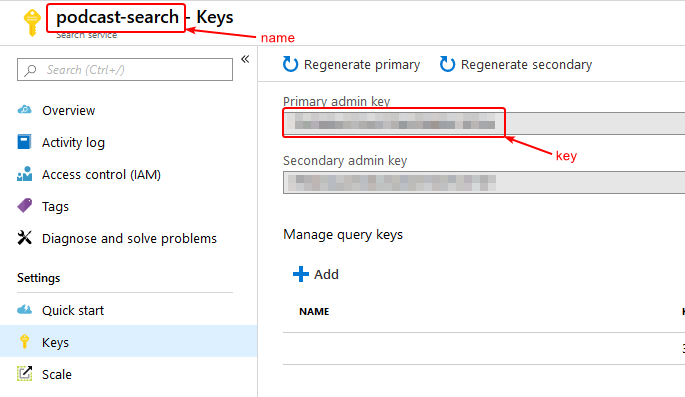
var searchClient = new SearchServiceClient("name", new SearchCredentials("key"));
Where "name" is the Search service resource name and "key" is one of the admin keys from Azure Portal.
Data source
Next step is creating a data source in Azure Search. In this case I'm using Azure Blob Storage (DataSourceType.AzureBlob) and pointing to the final folder in the test container.
string dataSourceName = "testsource";
string containerName = "test";
string folder = "final";
var dataSource = new DataSource()
{
Name = dataSourceName,
Type = DataSourceType.AzureBlob,
Credentials = new DataSourceCredentials("connection string"),
Container = new DataContainer()
{
Name = containerName,
Query = folder
}
};
searchClient.DataSources.CreateOrUpdate(dataSource);
Index
Next is index. It would be convenient to mirror the JSON file structure, but I wanted to use my own schema:
id= unique document identifierfile_name= Storage blob nameoffset= OffsetInSeconds from source fileduration= DurationInSeconds from source filecontent= text of the Display property inside NBest array of the source file
The index itself doesn't contain any field mappings, so the definition in C# is quite straight-forward:
string indexName = "testindex";
var index = new Index()
{
Name = indexName,
Fields = new List<Field>()
{
new Field("id", DataType.String)
{
IsKey = true,
},
new Field("file_name", DataType.String)
{
IsRetrievable = true
},
new Field("offset", DataType.Double)
{
IsRetrievable = true
},
new Field("duration", DataType.Double)
{
IsRetrievable = true
},
new Field("content", DataType.String)
{
IsSearchable = true,
IsRetrievable = true
}
}
};
searchClient.Indexes.CreateOrUpdate(index);
Indexer
Indexer is responsible for the transformation of JSON data in Storage blobs into search index fields defined in previous step. Let's see the definition:
string indexerName = "testindexer";
string targetIndexName = "testindex";
string dataSourceName = "testsource";
var indexer = new Indexer()
{
Name = indexerName,
DataSourceName = dataSourceName,
TargetIndexName = targetIndexName,
Parameters = new IndexingParameters()
{
Configuration = new Dictionary<string, object>()
{
{ "dataToExtract", "contentAndMetadata" },
{ "parsingMode", "jsonArray" }
}
},
FieldMappings = new List<FieldMapping>()
{
new FieldMapping("AzureSearch_DocumentKey", "id", FieldMappingFunction.Base64Encode()),
new FieldMapping("metadata_storage_name", "file_name"),
new FieldMapping("/OffsetInSeconds", "offset"),
new FieldMapping("/DurationInSeconds", "duration"),
new FieldMapping("/NBest/0/Display", "content")
},
};
searchClient.Indexers.CreateOrUpdate(indexer);
Key pieces here are:
parsingModeproperty is set tojsonArray.idfield is mapped to built-in propertyAzureSearch_DocumentKeywhich is necessary in order to get unique IDs per JSON object, otherwise only single entry per blob would be added to the index!file_namefield is mapped to another built-in property:metadata_storage_namewhich represents the file name in blob storage.contentfield is mapped to a property inside JSON array using the/NBest/0/Displaysyntax (1st element of the NBest array).
If the mapped field doesn't exist in the JSON document, it's just skipped without error. Thanks to this it's possible to index documents with different schemas.
This indexer runs only once after creation, because it doesn't contain any definition of schedule.
Done
If everything went fine, you should see how many documents were indexed and how much space it took in Azure Search.
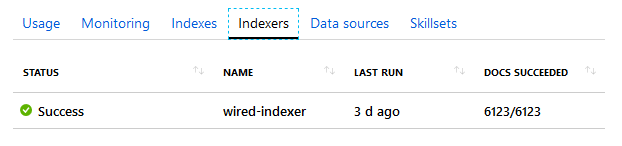
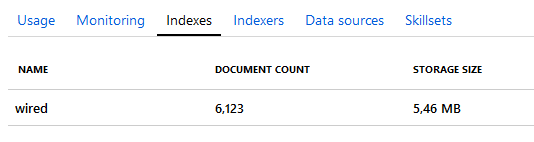
What happend to me at first was that the number of processed documents was 6000, but the index contained only 50. This happened because I didn't use unique IDs per document, but only per source file. Solution is the AzureSearch_DocumentKey.
Feedback
Found something inaccurate or plain wrong? Was this content helpful to you? Let me know!
📧 codez@deedx.cz