Bulk audio transcription in Azure
speech cognitive-services
August 20, 2019
Since Build 2019 the Azure Speech service supports bulk audio transcription for files stored in Azure Storage. The API is a little bit hidden, so this article describes how to work with it.
tl;dr
To perform bulk transcription, upload audio files to storage container, generate SAS URL and call:
POST https://<region>.cris.ai/api/speechtotext/v2.1/transcriptions
Ocp-Apim-Subscription-Key: <speech key>
Content-Type: application/json
{
"results": [],
"recordingsUrls": [
"<SAS URL>"
],
"models": [
{
"id": "bc803022-6339-4746-a0b1-27d97888bde0"
}
],
"locale": "en-US",
"name": "Bulk transcription",
"properties": {
"PunctuationMode": "DictatedAndAutomatic",
"ProfanityFilterMode": "Masked",
"AddWordLevelTimestamps": "False",
"AddSentiment": "False"
}
}
Detailed instructions follow.
Bulk transcription API
The batch transcript API has been part of the Speech service for a long time. What's new is the "bulk" funcionality. You just have to upload your audio files to Azure Storage, generate SAS URL for the container, initiate transcription, wait and finally download results.
Upload audio to Azure Storage
Thanks to the recent updates to the Speech service there's a high probability that you won't need to convert your audio files before uploading. In my experiments I took several podcast episodes and just uploaded them to Storage as MP3s and one M4A.
The tool I'm using to manage Azure Storage is Storage Explorer.
-
Create Azure Storage Account (or use an existing one).
-
Create a container in this account.
-
Upload your audio files.
Generate SAS URL for the container
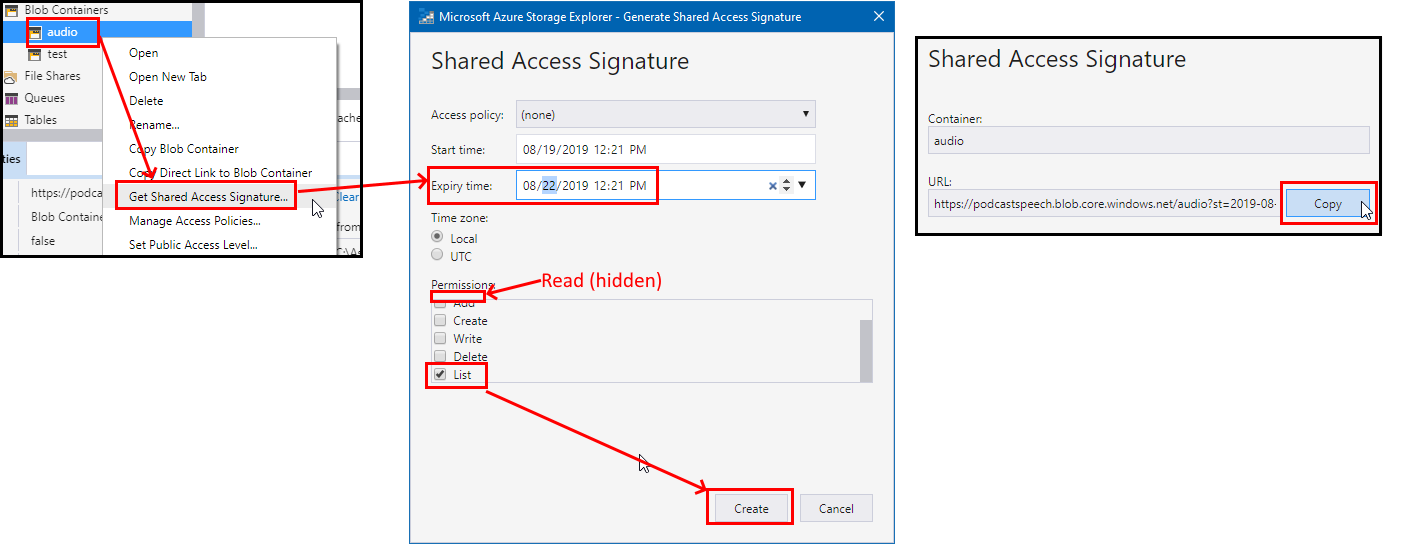
I use Storage Explorer as an easy way to generate SAS (Shared Access Signature) URL for a container. There are other options as well.
When getting SAS for this container keep the Read and List permissions.
Initiate transcription
Bulk transcription falls under the batch API endpoint, with one small catch - use version 2.1 instead of 2.0!
POST https://<region>.cris.ai/api/speechtotext/v2.1/transcriptions
Where:
<region>is where your Speech API key is provisioned (northeurope, westus etc.).
Headers:
Ocp-Apim-Subscription-Key: <speech key>
Content-Type: application/json
Where:
<speech key>is your Speech service API key.
Body:
{
"results": [],
"recordingsUrls": [
"<SAS URL>"
],
"models": [
{
"id": "bc803022-6339-4746-a0b1-27d97888bde0"
}
],
"locale": "en-US",
"name": "Bulk transcription",
"properties": {
"PunctuationMode": "DictatedAndAutomatic",
"ProfanityFilterMode": "Masked",
"AddWordLevelTimestamps": "False",
"AddSentiment": "False"
}
}
Where:
recordingsUrlsis an array of strings (note the difference from standard batch transcription'srecordingsUrl).<SAS URL>is the URL copied in the previous step (including all parameters).models.idis the GUID of acoustic model you want to use (can be baseline or customized).localemust correspond to the selected model ID.propertiesare standard properties of batch transcription.
You will know immediately that your request was successful if the API returns 202 Accepted status code. Otherwise the response body should contain information about what went wrong.
Wait
The transcription can take minutes, or even hours, depending on how much audio content you want processed. But overall it's shorter than the audio duration.
To check status of the transcription, you can periodically query the transcriptions API (with appropriate Ocp-Apim-Subscription-Key header):
GET https://northeurope.cris.ai/api/speechtotext/v2.1/transcriptions/
Beware that to get results from v2.1 endpoint, you have to query the 2.1 version every time. Data is not shared currently.
Or you can set up a webhook to proactively inform you about the completion.
Download results
Once the status is Succeceded you will get the resulting JSON object with the resultUrls property filled in:
{
"results": [
{
"recordingsUrl": "<SAS URL>",
"resultUrls": [
{
"fileName": "audio/file1.mp3",
"resultUrl": "<url>"
},
{
"fileName": "audio/file2.m4a",
"resultUrl": "<url>"
},
{
"fileName": "audio/file3.mp3",
"resultUrl": "<url>"
},
{
"fileName": "audio/file4.mp3",
"resultUrl": "<url>"
},
{
"fileName": "audio/file5.mp3",
"resultUrl": "<url>"
}
]
}
],
"datasets": [],
...
"statusMessage": "None.",
"id": "f0fbce11-535e-476e-af3e-22f6cd24193d",
"createdDateTime": "2019-08-19T11:33:29Z",
"lastActionDateTime": "2019-08-19T13:50:16Z",
"status": "Succeeded",
"locale": "en-GB",
"name": "Bulk transcription",
"properties": {
"PunctuationMode": "DictatedAndAutomatic",
"ProfanityFilterMode": "Masked",
"AddWordLevelTimestamps": "False",
"AddSentiment": "False",
"CustomPronunciation": "False",
"Duration": "02:54:49"
}
}
To download the final transcript for each file, just grab the URL and download it... :)
There's a new interesting property called CombinedResults which contains full transcript of the whole audio. The traditional SegmentResults follow beneath.
And that's it. Just don't forget to use the v2.1 API and all should work fine.
Feedback
Found something inaccurate or plain wrong? Was this content helpful to you? Let me know!
📧 codez@deedx.cz