How This Site Is Built - Continuously
September 2, 2017
Historically, I've been the PHP kind of blogger. I basically learned the programming language by coding a sophisticated guestbook component for my various websites. Dynamic blog engine followed (and is still running!), but then I finally realized that it's not the right time to write yet another MVC-CMS system and switched to WordPress. It works just fine, we use it at Microsoft and also my Czech dev-blog is powered by WordPress.
This post is about the next step, an evolution, which is a statically generated site. Let's dig into it!
tl;dr
I'm using Typora, Hugo, Git and Visual Studio Team Services to author posts and publish them automatically through continuous integration pipeline.
Motivation
One day I realized that I don't need the blog to by dynamic, to be generated from a database every time someone wants to read an article. I was posting only once a month, so there weren't many changes anyway.
Therefore, these were my requirements:
- Local & offline editing.
- Minimal in all aspects - disk space, design etc.
- Markdown as the authoring format (I got used to it way too much in the recent years).
- Backed by Git, so that It's possible to track changes and place it to a cloud source-control system.
- Automatically published when done editing.
- Transparent - content fully accessible in simple formats, no database "obfuscation".
Because of these reasons I chose a handy generator called Hugo, which builds the whole site from markdown files and HTML templates. But don't get me wrong - it's not THAT simplistic. It's actually capable of many things - check their site and go through some of their tutorials to learn more about Hugo itself.
Implementation
Editor
Blogging is writing. And for me the main tool to write markdown is Typora, Electron-powered cross-platform WYSIWYG editor.
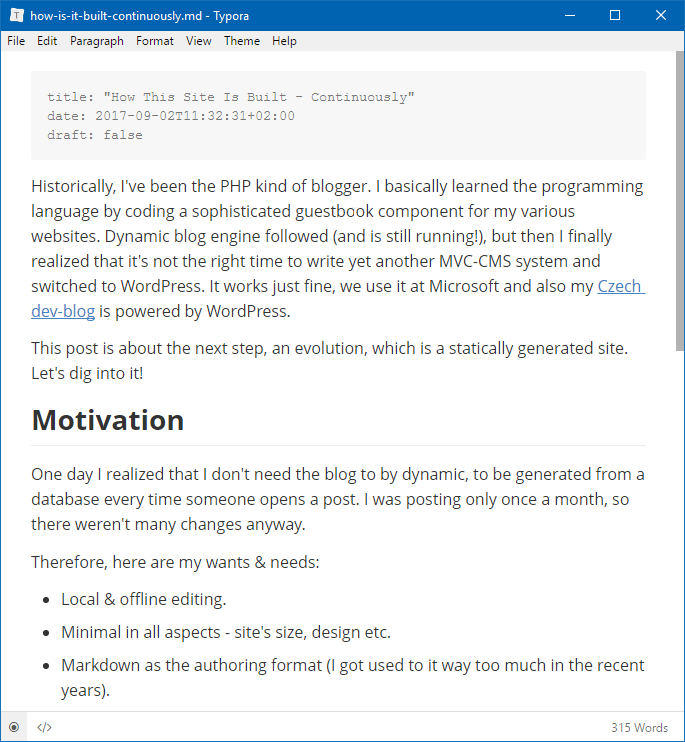
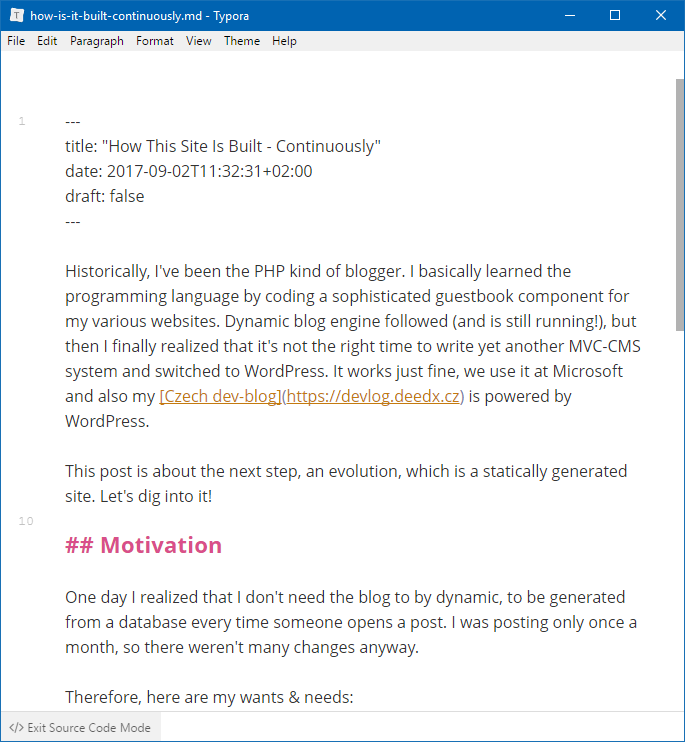
Typora works on Windows, Mac and Linux and is quite minimalistic. It allows you to edit the markdown code directly, if you so desire, but you don't have to. There are different visual themes available (I prefer GitHub) and once you learn a few keyboard shortcuts, you will get extremely productive. I mostly use:
- Ctrl+B, Ctrl+I for Bold and Italic (obviously),
- Ctrl+Shift+I to insert and image,
- Ctrl+K to create a hyperlink (and if there's a URL in clipboard, it will automatically fill it in!).
I also usually configure the root folder of images, as a parameter in every article's front-matter:
typora-root-url: ..\..\static
This parameter is used by Typora only and allows me to write image paths in the final form (that is /images/<article>/<filename>) and still see them in the editor.
Local Authoring
When I'm writing a post or making changes to the site, I always have Hugo running in server mode, so that it automatically picks up any changes and updates the browser window.
hugo server --baseUrl="http://localhost:1313/"
Then I navigate to http://localhost:1313 and see how the post will look like (it's like preview in WordPress, but live after each save).
Git Locally
If I wanted to continue editing the post on a different computer, I would commit & push it to Git and simply pull the repo elsewhere (or edit in the browser - we'll get to it).
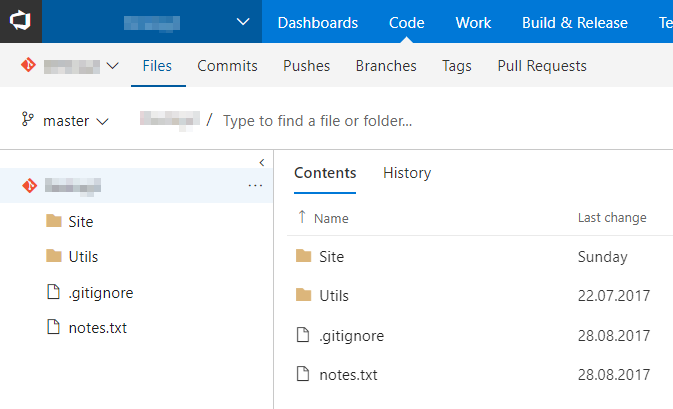
My whole blog is a Git repo. It has the following structure:
- .git
- Site
- content
- public
- static
- [... other Hugo stuff ...]
- config.toml
- Utils
- hugo.exe
- .gitignore
The Site folder is fully under Hugo's control. All posts and other markdown files are in the content subfolder and the static subfolder hosts all images. Hugo compiles all files into the public subfolder which is at the end deployed to the web server.
I decided to pack hugo.exe file together with the repo and placed it in the
Utilsfolder so that the build process can simply take the tool directly from the repo and run it. Updating also means to just replace the EXE with new version.[Update 01-2018]: This is no longer necessary as there's an extension for VSTS which provides Hugo as a build step.
Finally, .gitignore consists of a single line:
Site/public
The reason is simple - I use Hugo locally to preview and test articles before publishing. But for the live site I want Continuous Integration to generate content in the cloud on every change. I don't want the locally generated content to overwrite what I have online.
Git in the Cloud
With the post written, site designed and everything built to static HTML files I could simply upload the public folder to FTP server and be done with it. That wasn't enough for me, though. I wanted full Continuous Integration (CI) pipeline. Coming to the stage is Visual Studio Team Services (VSTS)!
VSTS offers free source control, automatic builds, release management, load tests and more. So each git push goes to my private Git repository and then jumps to the continuous integration machinery.
To store your source code in VSTS you have to create a Project and then go to Code and clone the repo. Or you can create the project, copy remote address and issue the git remote add command with an existing local repo.
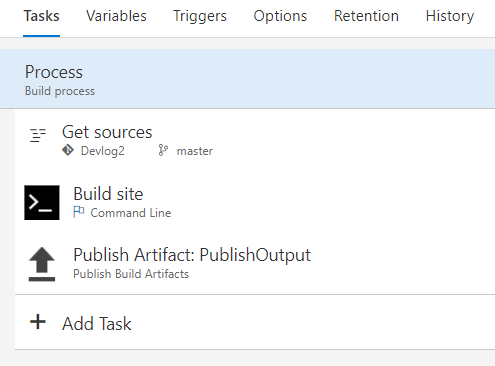
Blog source code is up, let's have a look at how it is actually built into a static website. It happens in the Build & Release part, where I've created a new Build Definition (from blank template) with three steps:
-
In the first step, the build machine just get sources from the repository: branch = master and don't clean (= false).
-
Second step is building the site using Hugo (we have hugo.exe in the repo, remember?):
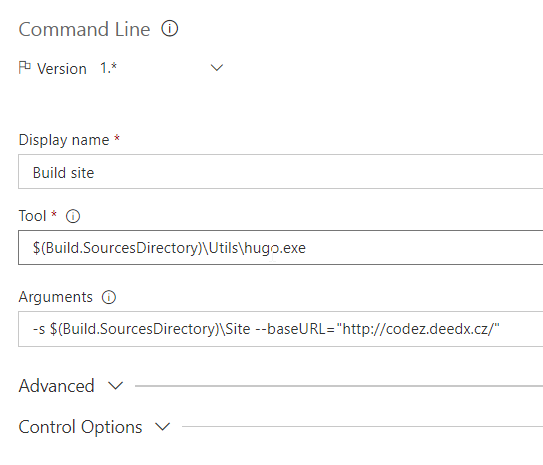
-
Third step is publishing build result (i.e. the
Site\publicfolder) and passing it to Release:
After these three steps, all posts are converted from markdown to HTML, merged with templates and along with images placed to the public folder. Let's switch to Release and continue the publishing process.
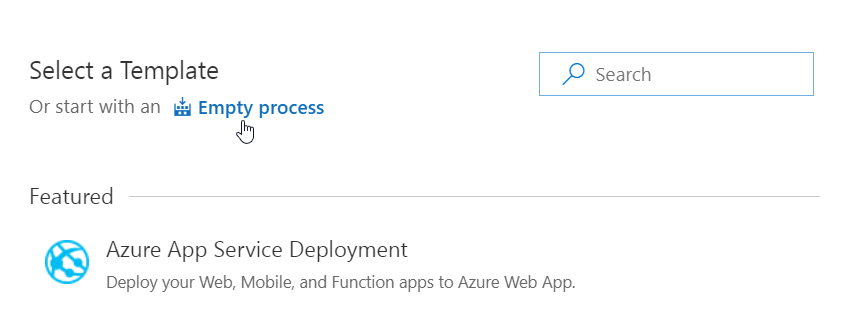
It starts with creating a new release definition with an Empty process:
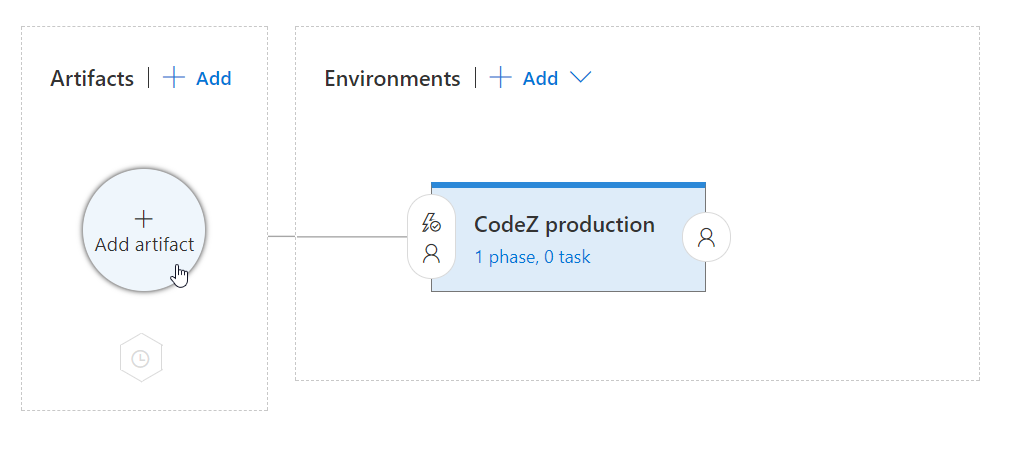
With one Environment:
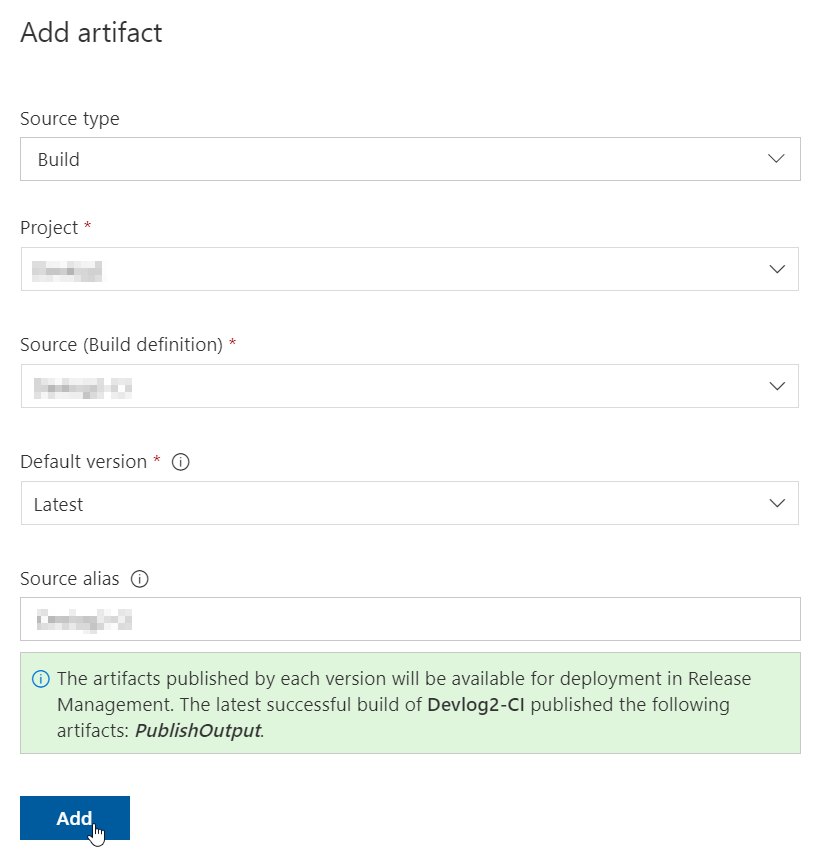
And artifact as the latest version from project build:
This creates a simple pipeline: "Take publish output from this build and send it to this environment". Next is turning on the continuous integration trigger so that the site is published every time there's someting new (i.e. after git push).
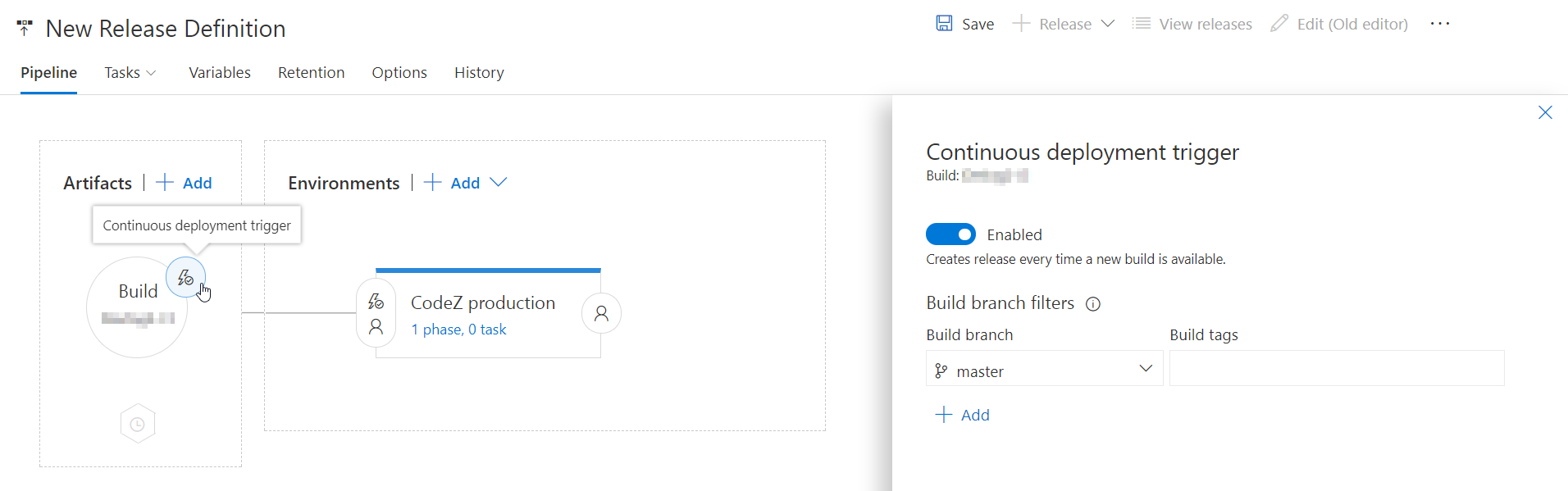
Finally I had to specify HOW exactly was the new version published. That is done in the Tasks section of the release definition.
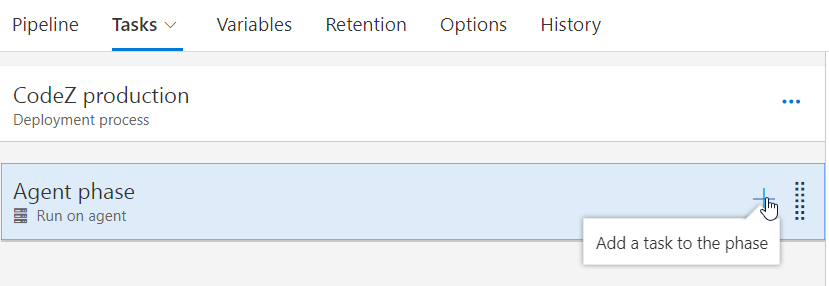
I clicked Add a task to the phase:
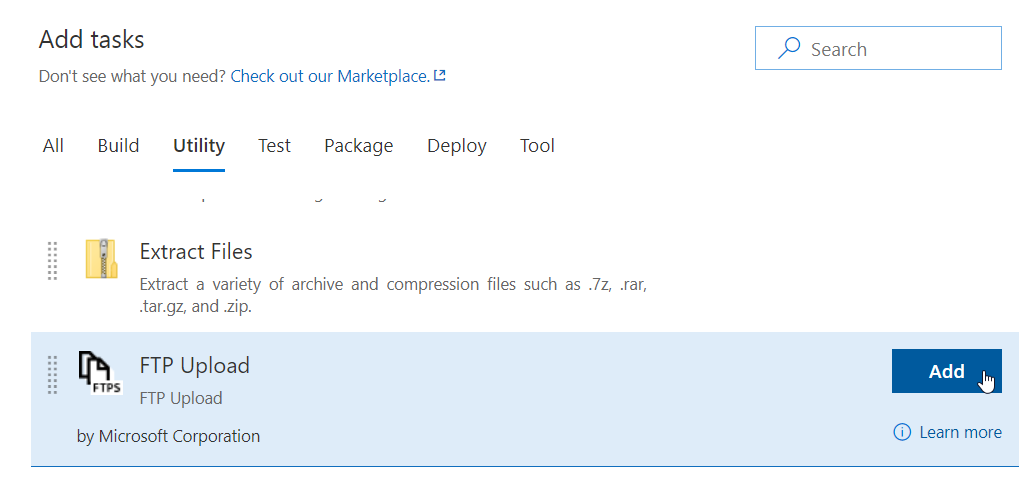
And chose FTP Upload from the Utility section:
This tasks required a few properties to be filled. So I specified my websites FTP address, username and password and source folder (remember? PublishOuput now contains the whole public folder).
Hint: If you can, create an FTP user dedicated just for this site with no access anywhere else. For security's sake ;)
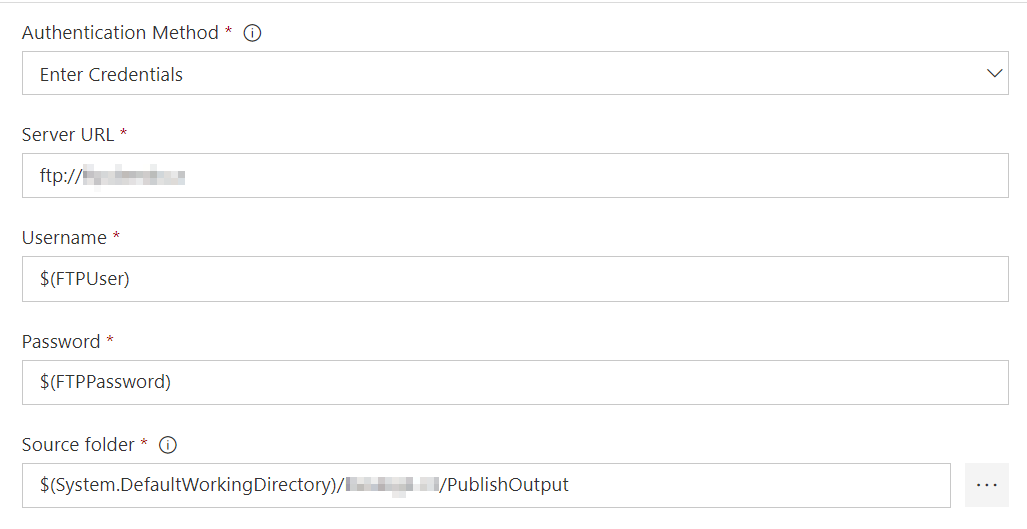
If you look closely at the picture, you can see two custom variables:
$(FTPUser) and $(FTPPassword)
These were set in the Variables section of the release definition and it's a good practice to sort of "mask" credentials like that. You can specify that any variable is a secret - therefore not retrievable.

When the time comes for the post to leave my local computer and fly up to the cloud, I do a simple Git Push:
git commit -am "New post!"
git push
Online Authoring
Imagine you want to quickly edit a typo. Your computer is nowhere near and you're not going to install Git and clone the repo to your parent's computer, are you?
Having the whole site's content stored as source code in a repository has several side benefits. One of them is the ability to edit anything in the browser and push changes through the same pipeline that I use from my primary PC.
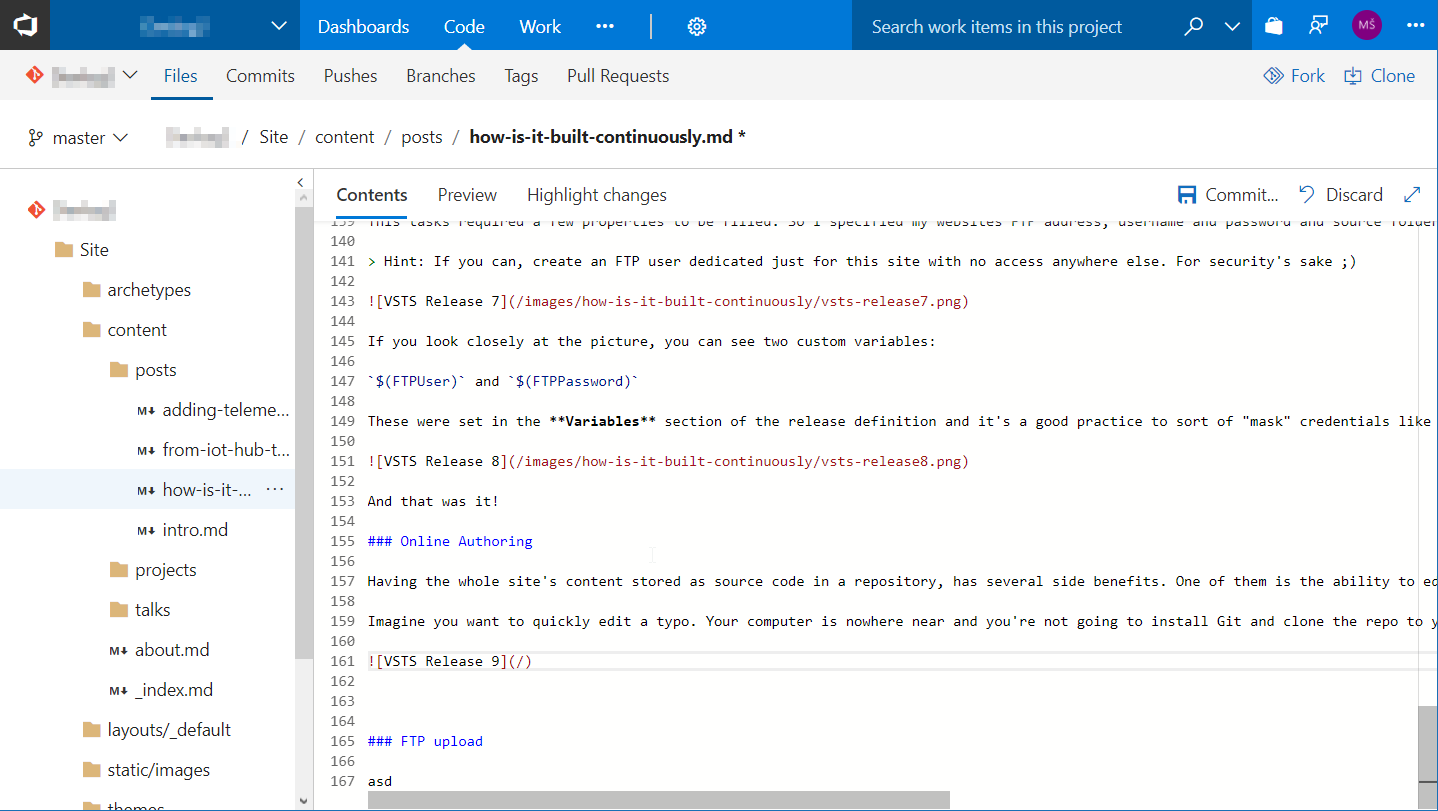
VSTS even has syntax coulouring and preview for markdown.
FTP upload
And of course, it's still just static HTML files, so if I had the desire to generate any piece of content locally or fiddle with files in poduction, I certainly could log in via FTP and browse the raw content of my site.
Summary
That's about it. Proper configuration took some time and serveral trials with many errors (and is still evolving), but I'm now happy with the publishing process - from editing to seeing the article online.
Feedback
Found something inaccurate or plain wrong? Was this content helpful to you? Let me know!
📧 codez@deedx.cz