Parsing SoundCloud RSS with .NET
rss soundcloud net static-web
January 15, 2019
If you're into podcasting, you've probably noticed that RSS is still alive! Podcasts are not downloaded directly from Apple Podcasts, Spotify, Google Play Music etc., these directories just aggregate your RSS feed, display information to listeners and redirect them to your audio file for listening/download.
What is this about?
This post describes the process of extracting information from SoundCloud RSS feed in C# to generate static website.
Background
My goal was to create a static website (no WordPress or other CRM) and avoid duplication of data input. Our podcast is hosted on SoundCloud, I already upload everything (MP3 file, image and description) to SoundCloud and don't want to do the same thing again for the website. And don't even get me started on updates...
First, I wanted to create my own API which would manage uploading to SoundCloud (through their API) and my website. Then SC (SoundCloud) closed the API for new submissions... so that was a no-go.
Second approach uses SC as the single source of truth and generates static files based on data published there. This is how the result looks:
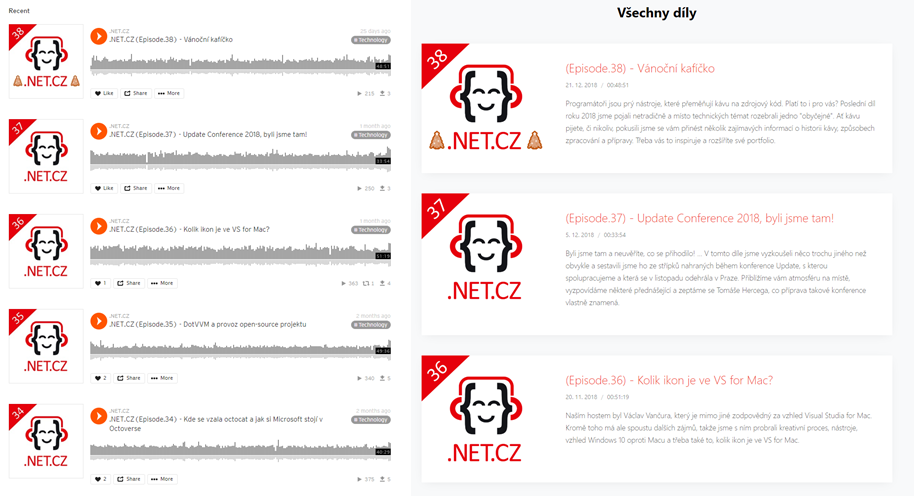
(Left) SoundCloud page - data source, (Right) Final website display
Without the API it's good that SC conveniently provides an RSS feed with all episodes, artwork, descriptions and other information. It looks like this:
<?xml version='1.0' encoding='UTF-8'?>
<rss version="2.0" xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<atom:link href="http://feeds.soundcloud.com/users/soundcloud:users:206444980/sounds.rss" rel="self" type="application/rss+xml"/>
<atom:link href="http://feeds.soundcloud.com/users/soundcloud:users:206444980/sounds.rss?before=316071514" rel="next" type="application/rss+xml"/>
<title>.NET.CZ</title>
<link>http://soundcloud.com/msimecek</link>
<pubDate>Fri, 21 Dec 2018 14:02:01 +0000</pubDate>
<lastBuildDate>Fri, 21 Dec 2018 14:02:01 +0000</lastBuildDate>
<ttl>60</ttl>
<language>cs</language>
<copyright>All rights reserved</copyright>
<webMaster>feeds@soundcloud.com (SoundCloud Feeds)</webMaster>
<description>Máme rádi C# a .NET a nemáme rádi, když se v podcastech moc tlachá. Proto jdeme rovnou k věci a buď sami, nebo se zajímavými hosty diskutujeme technologické novinky a vývojářská témata. Vše kolem 30-40 minut, tak akorát na cestu do práce.</description>
<itunes:subtitle>Máme rádi C# a .NET a nemáme rádi, když se v podc…</itunes:subtitle>
<itunes:owner>
<itunes:name>.NET.CZ</itunes:name>
<itunes:email>martin@deedx.cz</itunes:email>
</itunes:owner>
<itunes:author>Martin & Vojta</itunes:author>
<itunes:explicit>no</itunes:explicit>
<itunes:image href="http://i1.sndcdn.com/avatars-000336810693-s58ehz-original.jpg"/>
<image>
<url>http://i1.sndcdn.com/avatars-000336810693-s58ehz-original.jpg</url>
<title>.NET.CZ</title>
<link>http://soundcloud.com/msimecek</link>
</image>
<itunes:category text="Technology"/>
<item>
<guid isPermaLink="false">tag:soundcloud,2010:tracks/548233053</guid>
<title>.NET.CZ(Episode.38) - Vánoční kafíčko</title>
<pubDate>Fri, 21 Dec 2018 14:02:01 +0000</pubDate>
<link>https://soundcloud.com/msimecek/dotnet-cz-episode-38</link>
<itunes:duration>00:48:51</itunes:duration>
<itunes:author>Martin & Vojta</itunes:author>
<itunes:explicit>no</itunes:explicit>
<itunes:summary>Programátoři jsou prý nástroje, které přeměňují kávu na zdrojový kód. Platí to i pro vás? Poslední díl roku 2018 jsme pojali netradičně a místo technických témat rozebrali jedno "obyčejné". Ať kávu pijete, či nikoliv, pokusili jsme se vám přinést několik zajímavých informací o historii kávy, způsobech zpracování a přípravy. Třeba vás to inspiruje a rozšíříte své portfolio....</itunes:summary>
<itunes:subtitle>Programátoři jsou prý nástroje, které přeměňují k…</itunes:subtitle>
<description>Programátoři jsou prý nástroje, které přeměňují kávu na zdrojový kód. Platí to i pro vás? Poslední díl roku 2018 jsme pojali netradičně a místo technických témat rozebrali jedno "obyčejné". Ať kávu pijete, či nikoliv, pokusili jsme se vám přinést několik zajímavých informací o historii kávy, způsobech zpracování a přípravy. Třeba vás to inspiruje a rozšíříte své portfolio....</description>
<enclosure type="audio/mpeg" url="http://feeds.soundcloud.com/stream/548233053-msimecek-dotnet-cz-episode-38.mp3" length="117261699"/>
<itunes:image href="http://i1.sndcdn.com/artworks-000461988672-9ii6fi-original.jpg"/>
</item>
<item>
...
Besides standard RSS/Atom elements there are a few iTunes specifics - such as duration, explicit, podcast owner etc. This is very handy, because it gives me and every podcast aggregator all the information we need.
Parsing the feed in C#
So I wanted to extract episode information from the feed, generate MD files per episode and publish a static website based on those files.
This is how I do it:
// NuGet - available for .NET Core too!
using System.ServiceModel.Syndication;
using System.Xml;
...
public void Process(string feedUrl, string outputDirPath)
{
// XML reader is able to read from the internet ;)
var reader = XmlReader.Create(feedUrl);
// Load it into a SyndicationFeed for easier access.
var feed = SyndicationFeed.Load(reader);
foreach (SyndicationItem i in feed.Items)
{
Console.WriteLine($"{i.Title.Text}\t\t | | {i.PublishDate.ToString()}");
// "itunes:image" and "itunes:duration" are special tags, defined by iTunes, which are not part of the standard atom/rss namespace.
var imgEl = i.ElementExtensions.ReadElementExtensions<XmlElement>("image", "http://www.itunes.com/dtds/podcast-1.0.dtd")[0];
var durationEl = i.ElementExtensions.ReadElementExtensions<XmlElement>("duration", "http://www.itunes.com/dtds/podcast-1.0.dtd")[0];
// The title is always: NET.CZ(Episode.35) Text.
// I use this pattern to extract the episode number - this value alone is not part of the RSS feed.
var epIdStart = i.Title.Text.IndexOf("(Episode.") + "(Episode.".Length;
var epIdLength = i.Title.Text.IndexOf(')') - epIdStart;
var epId = i.Title.Text.Substring(epIdStart, epIdLength);
// Templates are regular MD files with {{ variables }} inside.
var template = File.ReadAllText("Templates/episode.md");
template = template
.Replace("{{ title }}", i.Title.Text.Replace(".NET.CZ", ""))
.Replace("{{ description }}", i.Summary.Text.Substring(0, i.Summary.Text.IndexOf('\n')).Replace("\"", "\\\""))
.Replace("{{ date }}", i.PublishDate.ToString("o"))
.Replace("{{ image }}", imgEl.GetAttribute("href")).Replace("http://", "https://") // <itunes:image href="http://i1.sndcdn.com/artworks-000443020836-t630jj-original.jpg"/>
.Replace("{{ duration }}", durationEl.InnerText)
.Replace("{{ trackId }}", i.Id.Split(',')[1].Split(':')[1]) // <guid isPermaLink="false">tag:soundcloud,2010:tracks/526336104</guid>
.Replace("{{ summary }}", i.Summary.Text);
if (!Directory.Exists(outputDirPath))
Directory.CreateDirectory(outputDirPath);
File.WriteAllText($"{outputDirPath}/ep{epId}.md", template);
}
}
There's a little bit of XML wrangling there. Most of the attributes conform to the RSS schema, but image and duration do not. That's why I used ElementExtensions (and it took me a minute to figure out how this works).
i.ElementExtensions.ReadElementExtensions<XmlElement>("image", "http://www.itunes.com/dtds/podcast-1.0.dtd")[0]; // hope that it's always the first element :)
Generating the site
I like Hugo (in fact, this blog is generated by Hugo too), so I'm using it for our podcast site as well.
Uploading
The site is hosted on Azure Storage, using the static website feature. It creates a new storage container, called $web where you upload your content (HTML, CSS, JS files...) and Azure will serve it from special URL as it would run on a webserver.
My site generator is Azure Function (with Hugo packaged inside), so it's pretty easy to upload the site using the Storage SDK.
Beware, at the time of this writing, it was not possible to use Functions bindings with the
$webcontainer! That's why I had to use theCloudStorageAccountetc.
CloudStorageAccount account = CloudStorageAccount.Parse(destinationConnString);
var client = account.CreateCloudBlobClient();
var container = client.GetContainerReference("$web");
// ... run hugo ....
// Taking all files from all subdirectories.
var files = Directory.EnumerateFiles($"{outputDir}\\public", "*.*", SearchOption.AllDirectories);
foreach (var f in files)
{
// Clean the file name to represent correct path.
var file = f.Replace("Out\\public\\", "").Replace('\\', '/');
// Create reference for the file in Azure Blob Storage.
var fileBlob = container.GetBlockBlobReference(file);
var ext = Path.GetExtension(f);
string contentType = null;
// There's a dictionary of extension - content type mappings to set proper ContentType.
if (contentTypes.ContainsKey(ext))
contentType = contentTypes[ext];
fileBlob.Properties.ContentType = contentType;
// And finally uplad the file.
await fileBlob.UploadFromFileAsync(f);
}
Setting the ContentType property correctly is very important. Otherwise all files will be application/octet-stream and browsers will try to download them, instead of displaying as HTML.
Feedback
Found something inaccurate or plain wrong? Was this content helpful to you? Let me know!
📧 codez@deedx.cz